In this case study, we processed The ARF Privacy Study3 survey data functions for frequency distributions, focusing on single-select and multiple-select questions. An ARF researcher, building on the 2021 and 2022 Privacy Studies which included topics like online privacy concerns and the customization of advertising through online behavior, then generated fresh insights for the 2023 survey. This involved exploring new questions not previously asked, such as perceptions of personalized advertising, and analyzing data across novel demographic segments, including education levels, race, and political affiliation, for the first time.
Next, we engaged AI tools – ChatGPT 4, Bard, and Claude AI – to assess their ability to interpret the survey data and we would then compare their analyses with human interpretations. The goal was to determine if these AI models could independently generate analysis based on the dataset and first training the LLMs on the Privacy Reports from 2021 and 2022.Since protected data should not be uploaded or shared with AI, a level of human pre-processing was required to remove any field that was not completely anonymized. For this survey, this included location data and IP address.
ChatGPT 4
The prompt:
The results:
ChatGPT 4 first segmented the privacy reports into distinct sections for focused analysis. ChatGPT 4 then extracted column headers from the dataset in batches of 50, requesting user input to determine the analyses needed for each subset. This iterative process of dialogue between the user and ChatGPT 4, although thorough, was time-consuming due to the dataset’s size (over 400 columns).
A notable aspect of ChatGPT 4’s performance was its contextual understanding and the ability to make nuanced adjustments. For instance, it advised normalizing frequency distributions for categorical data based on the count of non-empty responses, a detail that could easily be missed even by human analysts.
Additional Uses & Features:
Code Review: ChatGPT 4 was tasked with reviewing the primary function used in the analysis. In a code review, ChatGPT 4 checks for errors and suggests improvements for clarity and simplicity. The AI successfully provided an edited version of the function, making it easier to understand.
Documentation Writing: ChatGPT 4 also efficiently wrote documentation for the code, accurately and clearly explaining each step.
Both the code review and documentation writing demonstrated ChatGPT 4’s ability to quickly and effectively understand and fulfill these specific tasks, showcasing its utility in streamlining the coding process.
Takeaways for ChatGPT 4:
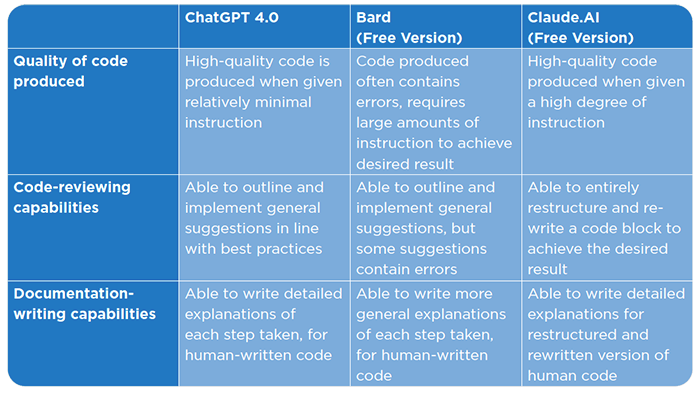
Overall, ChatGPT 4 is the strongest AI model when it comes to survey analysis. It consistently produces accurate code and requires the least amount of back-and-forth to achieve the desired results. Because ChatGPT 4 could parse the 2021 and 2022 Privacy Reports, as well as the full data set containing survey responses, it stood out as the model with the most human-like approach to performing the survey interpretation, displaying the ability to translate the contents of the previous reports into data analyses, then write the code for these analyses and return a final number. Since it can output final numbers (rather than chunks of code that the user would have to execute themselves, like in the other two models), ChatGPT 4 is also the ideal choice for users who do not have a programming background.
Bard
The prompt:
The results:
The case study reveals challenges encountered with Bard in generating code according to specific requirements:
- Initial Misinterpretation: When asked to create code for calculating a frequency distribution for a specific column, Bard initially produced code that calculated the mode for every column in the data frame, indicating a deviation from the requested task.
- Requirement for Detailed Guidance: Subsequent interactions with Bard necessitated explicit instructions on the exact Python methods to be used. Despite recognizing the difference between calculating the mode and a frequency distribution, Bard struggled to autonomously generate the correct response.
- Need for Extensive User Intervention: Bard required considerable user guidance to identify and correct these inaccuracies. The case study includes an experimental assessment (See below) that aimed to determine the level of input Bard needed to correct an error in its initial code composition.
Incorporation of Unspecified Parameters: Bard introduced additional inaccuracies by adding unspecified parameters into the method. These discrepancies were significant as they either stemmed from misinterpretation of the directives or resulted in code that could cause errors regardless of the data input.
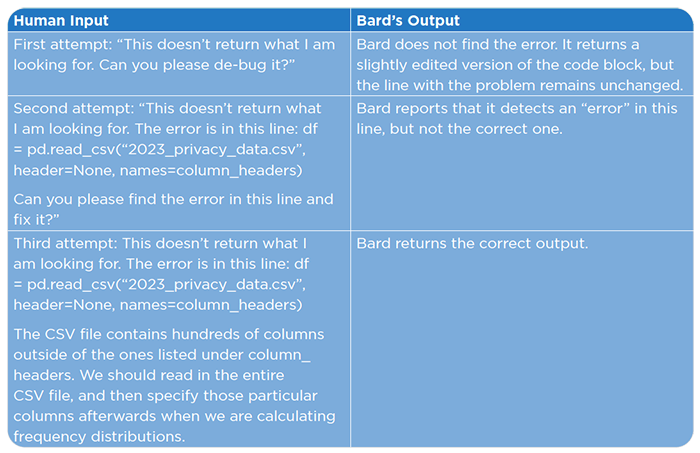
As shown, Bard is unable to detect its own errors unless it is shown exactly where and what the error is, somewhat defeating the purpose of using the assistance of an AI platform altogether.
Importantly, Bard holds very little context, “forgetting” previously mentioned information or errors that were previously corrected in the conversation. According to the FAQ section, this is intentional, but it makes survey interpretation with the model a lengthier process in that the same bug or error must be addressed multiple times.
Additional Uses & Features:
When it comes to reviewing previously written code, Bard was able to give some suggestions for increased readability. However, other suggestions it gave were incorrect and would have resulted in errors if implemented. Bard’s ability to write documentation for previously written code was strong, on par with ChatGPT 4.
Takeaways for Bard:
Relative to the other two models, the analytical process with Bard was less fluid. The generated code frequently contained errors, and the model could not rectify these inaccuracies without explicit directives pinpointing the exact nature and location of the mistakes. While the prospect of analyzing a dataset stored in one’s Google Drive is enticing, the current functionality falls short. Specifically, we encountered challenges in prompting Bard to access or provide summaries of even text-centric files within our Google Drive.
Claude AI
The prompt:
The results:
When given general instructions to perform analyses on the sample data set given the 2021 and 2022 Privacy Reports, Claude AI returns pseudocode that is based on the reports, but not on the data set. Whether this is due to copyright issues or the model’s inability to parse so many input sources is unclear. However, when given instructions to perform a specific analysis relating to the report, or to write a general function to be used for the report, Claude AI will generally return code that achieves the desired result.
Additional Uses & Features:
Claude AI can “Code Review.” Rather than returning a slightly edited version of our code, Claude AI completely restructured it, returning an entirely new design that still achieved our desired output. In practice, the result was unrecognizable from the original code thus making it difficult to understand each step. However, the model’s ability to immediately grasp the intent of the code block, and write a new code block from scratch rather than making copy edits to the original is very impressive.
Claude AI’s ability to write documentation was not as strong as the other two models. The result was a surface-level description of the steps being taken, which required a large amount of context to understand. Claude AI did not include descriptions of each function, including lists of inputs, which is generally standard practice.
Takeaways for Claude AI:
Claude AI demonstrates a commendable capacity for survey interpretation, positioning it as more adept than Bard but less robust than ChatGPT 4. Owing to copyright constraints, it generates code only under precise directives. Although it can access the entire dataset, it will replicate column names and inherent data values exclusively when samples are directly fed into the text interface. When tasked with a code review, Claude AI undertook a comprehensive reorganization of the code, yielding the desired output but diverging significantly from the approaches of the other two models.
Key takeaways:
- AI can be helpful in Survey Interpretation by writing code that can be used to analyze data. When given very specific instructions, all 3 models (ChatGPT 4, Bard, and Claude AI) can provide code that can produce certain summary statistics or charts to aid in data analysis.
- None of the models tested can perform front-to-back analysis (although ChatGPT 4 is the closest to this capability). They cannot ingest large data sources and output the results based on a vague or open-ended question, such as: “Perform an analysis on the results of the privacy survey based on the privacy reports from previous years.” Their “creativity” when approaching problems is limited and operate best when given strict instructions for execution.
- Performing analysis with AI is an iterative process. AI’s first attempt at writing code is almost never correct, but it can reach the correct output with additional feedback or details. This back-and-forth is time consuming, but certainly has the potential to increase efficiency if one does not have a high degree of familiarity with the programming language being used.
- In addition to writing the code to perform the analysis itself, AI can potentially be used to support technical work in the form of:
- Parallel processing – Performing an analysis, having AI write a version of the code, then running both and comparing the output as a method of checking one’s work.
- Code reviews – Analyzing code that was previously written and editing it for increased clarity, conciseness, and reproducibility.
- Documentation – Writing annotations in previously-written code with descriptions for what is being done at each step, making it more seamless for future collaborators to understand the processes that were performed.
For a more detailed review of the prompts and LLM responses see.
3 The ARF Privacy Study is an annual survey conducted by the ARF that examines American perspectives on privacy, data collection (particularly in advertising), trust in institutions like medical, financial, and government bodies, and understanding of digital advertising terms. In its sixth year, 2023, the study gathered over 1,300 responses from U.S. participants, ensuring diversity in age, gender, and regional representation.