This case study highlights the utilization of AI in crafting survey questions, emphasizing its role in streamlining the process and generating innovative ideas. Our findings show that AI for survey design is a repetitive but time-saving method. We’ll demonstrate this through examples, specifically in the context of media research surveys. While our primary focus is on Advertising Research, we’ve also employed AI, particularly Large Language Models (LLMs), in creating Awareness and Usage surveys. This includes integrating prominent brands into the surveys and adapting them for different regions, like modifying a survey for Mexico by substituting U.S. brands with leading Mexican ones. The findings of this case study underscore the utility of using AI for designing survey questions yet highlight the need for iterative
prompting and refinement in AI-assisted tasks.
Our initial prompt for all three AI platforms was as follows:
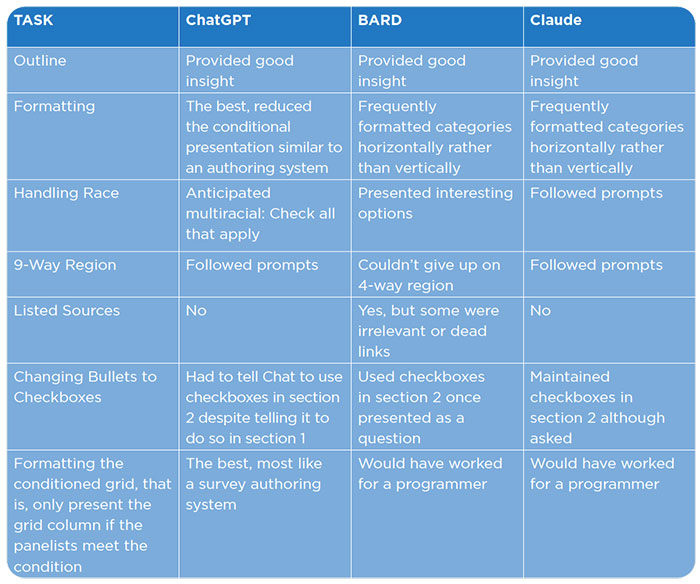
All three models produced reasonable outlines for the survey generally starting off with demographic questions, then moving to television services and then streaming services.
ChatGPT 4
Initially, ChatGPT 4 included ‘Household Income’ in ‘Basic Demographic Information’ section but moved this to end of survey upon request. It also neglected to include ‘Race and Ethnicity,’ and added this once requested.
ChatGPT 4 was effective in formatting questions similar to a survey authoring system, showing strong capabilities in handling race and region questions. Although at first, ChatGPT 4 combined ‘Race’ with ‘Ethnicity,’ it easily revised this upon prompt. While Bard provided a wider variety of choices for racial identity, Chat’s use of a “check all that apply” format suggested a more nuanced understanding of multiracial identities.
In addition to providing an outline to the survey, ChatGPT 4 included ‘Best Practices for Question Design,’ underlining the importance of clarity, neutral wording, balanced answer options, and pilot testing, among other things.
ChatGPT 4’s output was more easily prompted into a format that a programmer would create for an online survey. This model demonstrated adaptability in conditional question presentation, where questions dynamically changed or were suppressed based on previous responses.
To sum, while ChatGPT 4 required initial assistance with formatting, it demonstrated a rapid learning curve. Its capability to dynamically present device-related questions was notably superior compared to other LLMs. If the API were integrated into a system, the process could be further streamlined. By assigning names to specific question formats, the instructions for creating surveys could be greatly simplified, relying on these predefined formats for guidance.
Bard
Bard had issues with maintaining a vertical format for answers.
This model struggled with adapting to a 9-way region question, often defaulting to a 4-way region format.
It listed sources for its responses, although some were irrelevant or dead links. For instance, Bard provided ‘Internships at Mystic Seaport Museum’ as a link for choosing Race and Ethnicity categories, and www.freedoniagroup.com/industry-study/recreational-vehicles-in-the-us-by-product-6th-edition-3624.htm, which is a dead link.
Bard provided diverse options for race and ethnicity questions. For instance, for Race, it gave the following response:
Race (choose option based on your target audience and research goals):
- Option 1 (US Census Bureau standard):
- White (including Hispanic or Latino)
- Black or African American
- American Indian or Alaska Native
- Asian
- Native Hawaiian or Other Pacific Islander
- Some Other Race
- Two or more races
- Prefer not to say
- Option 2 (Broader categories):
- Caucasian
- African American/Black
- Asian American
- Native American/Indigenous
- Other
- Multiracial
- Prefer not to say
- Option 3 (Additional granularity, consult with survey experts for appropriateness):
- White (Non-Hispanic)
- White (Hispanic)
- Black or African American
- Asian Indian
- Chinese
- Filipino
- Japanese
- Korean
- Vietnamese
- Other Asian
- Native Hawaiian or Other Pacific Islander
- American Indian or Alaska Native (Tribal Affiliation)
- Some Other Race
- Two or more races
- Prefer not to say
Claude AI
Claude AI quickly adapted to changes in question format, such as switching from bullets to checkboxes, but had some spacing issues in its formatting.
It had a faster response to requests for a 9-way region question compared to Bard and showed decent performance in conditional presentation of devices.
Claude AI initially placed demographic questions at the end, which was later adjusted upon request. Similarly, it did not initially include education, race, and ethnicity in demographic.
It eventually got to a concise conditional presentation of devices but was not as elegant as ChatGPT 4’s version.
Key Takeaways
- Flexibility and Adaptability: ChatGPT 4 outperformed the other models in adapting question formats and conditional presentation, making it more suitable for drafting surveys that resemble those created by professional survey programmers.
- Handling issues of Race and Ethnicity: Bard offered interesting options for race and ethnicity but was less flexible in adapting to specific survey structures like the 9-way region format.
- Speed and Formatting: Claude AI showed quick adaptability in question formatting and adjusting to specific requests, such as the 9-way region question, though it was less
elegant compared to ChatGPT 4’s version. - Learning and Improvement: The use of these LLMs in survey design demonstrated a learning curve, where the quality of output improved with more specific and refined prompts over time.
- Overall Effectiveness: All three AI systems represent effective methods for beginning a survey draft, with each having unique strengths and weaknesses in various aspects of survey design. We expect a frequent user of these LLMs would learn how to better prompt after programming a few surveys.
For a more detailed review of the prompts and LLM responses see.