In this case study, we examine AI’s report writing capabilities. To do so, we use two different case studies: the ARF Privacy Report (September 2024) and the Erwin Ephron project5 While the first is a deep investigation into how AI can be utilized for writing reports that are based on quantitative data analysis, the latter focuses on AI’s capabilities to consolidate a book based on qualitative texts, including summarizing and reinterpreting newsletters, and organizing the bulk of texts into separate segmentations according to thematic logic. For both case studies, AI proves to be a useful tool for crafting the reports, despite obvious differences between the quantitative and qualitative data that informs each report. However, the process in which each report was crafted differ significantly, with each necessitating human guidance, involvement, and heavy editing and scrutiny, at different points throughout the process.
2023 Privacy Report:
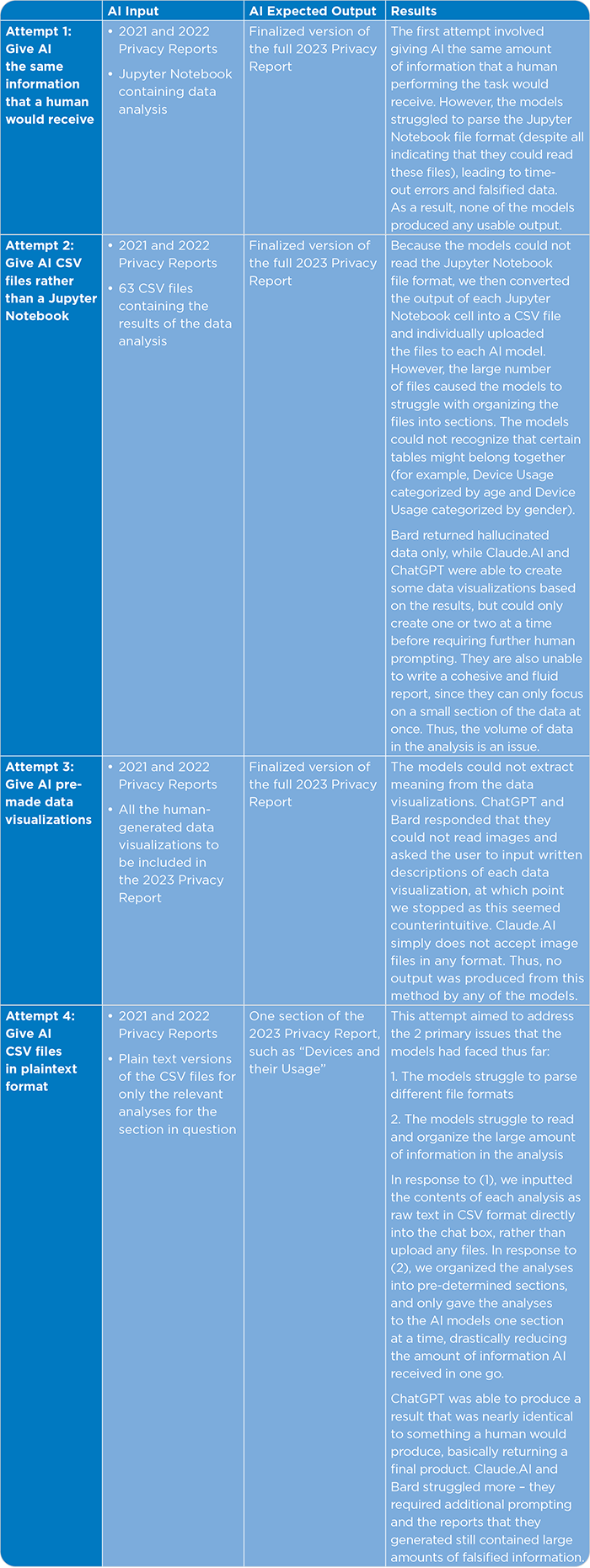
For the Privacy Report, we conducted a comparative analysis of the process and the final outcomes between the report crafted by humans and the one generated by AI. The key finding is that the most effective strategy involved creating an outline and then providing the AI model with relevant tables in plain text (not in CSV format) to write sections of the outline. The AI-generated report was found to be impressively similar to the report created by a human. However, the AI models faced challenges when trying to write the report with the same inputs a human would use, such as the 2022 and 2023 Privacy Reports and Jupyter Notebook outputs of data analyses. The models struggled to parse input files and could only interpret data successfully when the analysis results were directly copied and pasted into the text box.
The models also faced difficulties in composing the entire report coherently. They would maintain relevance for a few paragraphs before beginning to “hallucinate,” veering away from the original data they were provided with. Consequently, dividing the report into distinct sections and directing the AI to write each section individually is essential for maintaining focus and accuracy.
A major concern in employing AI for report writing emerged with the recurring issue of Claude AI and Bard fabricating data. These models frequently produced statistics that appeared plausible and were like those generated for the report, yet the figures were inaccurate. Since these are language models, it’s crucial to meticulously verify all numbers and figures to ensure they are derived from actual data, rather than being artificially generated by the AI. In contrast, ChatGPT 4 proved to be an effective asset in report creation, provided that the initial organization of ideas is complete, and the data is already formatted for readability.
Additionally, both Bard and ChatGPT 4 have the capability to generate data visualizations given specific data inputs,6 offering a time-efficient alternative to manually creating charts and graphs. Notably, ChatGPT 4 does this with a lot more ease and accuracy than Bard.
These findings highlight the need for converting data analyses into a format that AI can easily process and to thoroughly scrutinize anything an AI system does.
How the ARF Research Department Created the Report:
The process of composing the report began with a review of ARF Privacy Reports from previous years to understand their style and framework. Based on this we developed an outline, ensuring it included both recurring historical analyses and the outcomes of new questions introduced this year.
For every section, we examined the data to identify significant trends for emphasis and determined the most effective way to present these trends, creating data visualizations as needed to underscore key points. The writing phase involved weaving the relevant data analyses and visualizations into a cohesive narrative, providing necessary context or explanations for certain trends. Finally, we prepared a summary of the main trends for the report’s introduction and crafted a conclusion discussing the broader implications of the privacy survey for the report’s finale.
How AI Created the Report:
Ideally, an AI model would process the same inputs as a human, in this case the results from a data analysis in a Jupyter Notebook and reports from previous years, and generate a structured report inclusive of data visualizations. Nevertheless, our experience revealed that AI platforms necessitated substantial direction to yield practical outputs. We experimented with multiple approaches to steer the AI towards generating effective results, eventually identifying the most successful strategy.
Optimizing AI for Data-Driven Report Writing: Strategies, Challenges, and Solutions:
- The most effective strategy for using AI to write a report from data analysis involved creating an outline and supplying the model with relevant tables in plain text format for writing individual sections.
- ChatGPT 4 generated reports remarkably similar to those created by humans when provided with these specific parameters.
- AI models were unable to write reports using the same inputs as humans (relying solely on the 2022 and 2023 Privacy Reports and the Jupyter Notebook output).
- The models struggled with parsing input files and could only interpret data successfully when it was directly copied and pasted into the text box, making data conversion time consuming.
- AI models tended to stay accurate for a few paragraphs before deviating from the provided data, necessitating the division of the report into sections for AI to handle effectively.
- A major issue with AI report writing was the use of fabricated data by models like Claude AI and Bard, which often presented plausible but incorrect statistics.
- It’s essential to double-check numbers and figures provided by AI models to ensure they are based on actual data.
- can be a valuable tool in report writing, particularly after ideas are organized and data is made AI-readable.
- Both Bard and ChatGPT 4 can create data visualizations from specific data inputs, offering a time-efficient alternative to manually crafting charts and graphs.
Wow: The Wit and Wisdom of Erwin Ephron
Between 1993 and 2010, Erwin Ephron, a highly influential figure in the field of advertising and media planning, published The Ephron Letter, over 150 newsletters that were for many in the industry a must-read for staying informed about the latest trends, theories, and discussions in the rapidly evolving world of media and advertising. In honor of his talents, The ARF published Wow: The Wit and Wisdom of Erwin Ephron, in January 2024 in tribute to Erwin’s insightful analysis, commentary and critique. The full publication will be gifted to ARF WIDE (Workforce Initiative for Diversity and Excellence) contributors in early 2024.
Upon receiving the 150+ newsletters, we decided to utilize ChatGPT 4 to do the following:
- Thematically organize the newsletters
- Summarize each newsletter
- Reinterpret each newsletter according to the current media landscape
The main challenges encountered in this project involved text uploading and accurate segmentation.
- It was not possible to upload the PDF document without retaining chat history, a concern for handling sensitive materials. However, for the Ephron project, this was not a critical issue since the newsletters were previously published.
- ChatGPT 4 had difficulty accurately segmenting the newsletters (150 newsletters in one PDF), failing to distinguish where one newsletter ended and another began, which was vital for summarizing and identifying themes.
- To address this, the PDF was manually converted into 150 separate Word documents, one for each newsletter.
- Another hurdle was the limit on uploading more than 10 documents at a time, making the process of uploading 150 documents laborious and time consuming.
- Once uploaded, ChatGPT 4 effectively summarized each text and reinterpreted each newsletter in the context of the current media landscape.
- For the book outline, ChatGPT 4 initially categorized the newsletters into sections based on suggested themes, which could be adjusted as needed.
- ChatGPT 4 was also asked to compare its outline with one created by the ARF, highlighting the strengths and weaknesses of each approach.
- Deciding on 10 sections, there were issues in distribution: ChatGPT 4 created duplicates and unevenly divided the newsletters among segments, leading to skewed distribution.
- The re-categorization attempts encountered several errors, resulting in a heavily skewed final distribution with many categories lacking newsletters.
- Ultimately, ChatGPT 4’s suggested segmentation did not accurately reflect the content, requiring manual re-segmentation.
In sum, while ChatGPT 4 demonstrated effectiveness in summarizing individual newsletters and adapting their content to the current media landscape, it struggled with accurately segmenting a large collection of newsletters into coherent thematic sections. The AI encountered difficulties in processing a bulk PDF and required the content to be converted into individual Word documents. Even after this conversion, the AI’s limitations in handling large-scale document organization became apparent, leading to issues like duplicate entries and uneven distribution across categories. This necessitated manual intervention for accurate categorization and segmentation of the newsletters for the project.
For a more detailed review of the prompts and LLM responses, see.
5 For this case study only ChatGPT 4 was used.
6 Bard, for instance, needs the data to be uploaded through in the format of a CSV file.