Academic literature on using LLMs as substitutes for traditional advertising research is quite sparse. Currently, two primary methods to assess the viability of LLMs in advertising research are explored, offering insights into public opinion and consumer behavior:
- Direct Questioning with LLMs: This approach involves posing specific questions to an LLM, relying on its training and search capabilities to generate responses that mirror published reviews, recommendations, surveys, press releases, and other sources, essentially replicating an actual research program. A caveat here is that online reviews might not be fully representative of the general population, similar to the limitations of online convenience surveys.
- Creation of Synthetic Panels: This method involves creating a simulated panel of respondents that mirrors the attitudes of the target population, offering longitudinal consistency for tracking changes over time. When properly stratified, such synthetic panels can reflect the known demographic distributions of the relevant population. With an assumed 100% response rate, there would be no need for post-stratification adjustments.
Do LLMs Provide Estimates Similar to Those Collected Through ARF Primary Research?
In this case study, we explore whether LLMs can be a viable alternative for data collection, reflecting a broad spectrum of sources such as social media, reviews, and recommendations. Posing a series of questions similar to those used in the ARF’s Sixth Annual Privacy Survey and DASH Survey, we evaluate how closely these AI systems could replicate the results of more quantitative research. The performance of ChatGPT 4 is quite impressive. Indeed, all three AIs provided conceptual and good analysis, showcasing their ability to understand and interpret advertising content.
Estimating Trust in Police and Media
Our prompt:
Findings
- ChatGPT 4 yielded consistent findings with the ARF’s Privacy Surveys over the last three years.
Our prompt:
Findings
- ChatGPT 4 yielded consistent findings with the ARF’s Privacy Surveys over the last three years.
- Bard and Claude AI offered more comprehensive answers, reflecting the diverse estimates obtained from different surveys.
Media Behavior
Our prompt:
Findings
- Bard and Claude AI provided answers that went beyond the initial query, offering a more thorough response.
- However, Claude AI cited older information, referencing a Nielsen report from 2021.
Additionally, Claude AI’s representation of the Nielsen data appeared to be inaccurate.
Our prompt:
Findings
- The LLMs reported figures close to the ARF DASH report statistics, drawing from at least one source.
Creating Synthetic Survey Panels
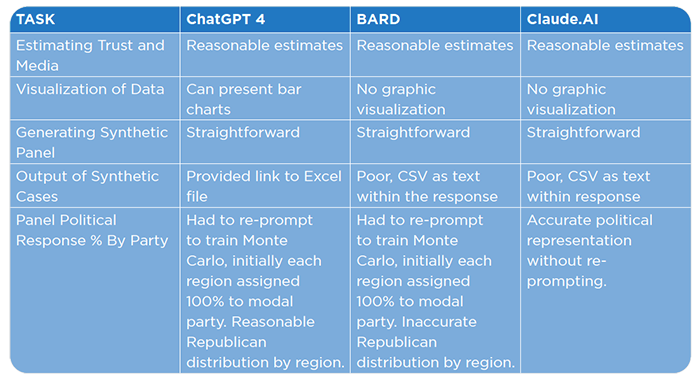
Some scholars propose that using a synthetic panel of respondents can grant users more influence over the responses of LLMs. This can be achieved by tailoring responses to account for variations in demographics and regional attitudes. For instance, instructing an LLM to respond from a specific viewpoint, such as that of a researcher or marketer, can yield different answers. The concept of a synthetic panel enables users to simulate a range of controlled variables. To illustrate, we conducted a basic example of constructing a synthetic panel. Our findings show that all three AI models could straightforwardly generate synthetic survey panels, simulating respondents based on demographic data. You can task the LLM to assign synthetic respondent case ids and typical demographics for the regions, far more accurate control would be to provide estimates that captured all the interaction effects. So, you could task the LLMs to set the panels political preference to mimic the national distribution, answers about politics would be far more accurate if the panel was set by political preference by age by region of the country, …. . This approach demands meticulous attention to detail for each survey question to be effective – unless, of course, there’s an emerging market dedicated to crafting high-quality synthetic panels.
For this test, each LLM was provided the marginal (not nested as recommended) demographic distributions for the US population. Then it was prompted:
All the LLMs could reasonably create such a panel with marginally accurate demographic distributions, although how the distributions were provided differed in that only ChatGPT 4 and Claude AI could ingest the data as an excel file.
Then each was asked:
Results
ChatGPT 4
ChatGPT 4 initially reported everyone in a region as having the modal political preference of the region. For, example everyone from the South was assigned as a Republican. We then had to re-prompt:
While not ready for real analysis, this worked as each region had a varied distribution of political parties that reflected the distributions widely available on the internet.
At least for ChatGPT 4, using the API and with a significant amount of curation, a synthetic panel may be a way of improving LLMs as an alternative to conducting survey research.
Bard
Adeptly generated a synthetic panel and accurately represented the provided demographics. However, its estimations of political affiliations within the Monte Carlo model were excessively high. The political distributions heavily skewed towards Democrat affiliations, although the sum of the three affiliations (Democrat, Republican, and Independent) did correctly total 100% for each region.
When asked to display a bar chart showing the demographic distributions of the panel Bard required more complex data ingestion processes and lacked graphic visualization capabilities.
Claude AI
Claude AI provided the most accurate and direct simulated political affiliations without needing re-prompting. Overall, the distribution of the political parties is consistent with published estimates.
Claude AI doesn’t do any form of visualization (bar chart) and its CSV format is textual and difficult to export without coding.
Key Takeaways:
ChatGPT 4 was the easiest to use due to its superior input and output abilities.
Claude AI produced the most reasonable estimates for political affiliation, aligning with published data.
While the AI models can simulate research processes, they will require careful curation and control of variables to provide an alternative to survey research.
This section was only intended to illustrate how to go about creating a synthetic panel and not to judge how accurate they would be. We spent at best a day experimenting with different prompts at a marginal level of demographic control – clearly insufficient to mimic the US adult population. Monte Carlo was one solution to an obvious failure. A real development program likely will have to catalogue all the failures and find solutions for the many kinds of failures that are likely to exist.
For a more detailed review of the prompts and LLM responses, see.